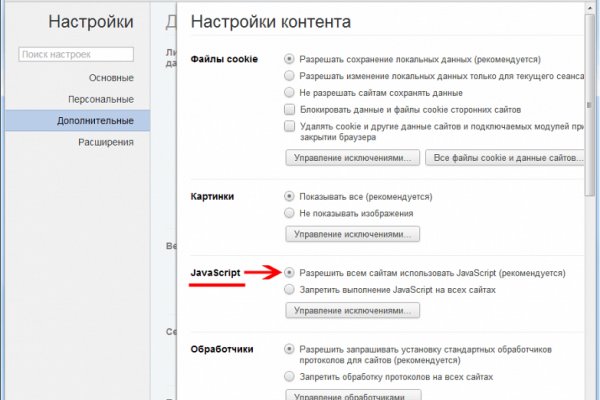
Не работает сайт blacksprut сегодня blacksprutl1
Можно узнать много чего интересного и полезного. Репутация При совершении сделки, тем не менее, могут возникать спорные ситуации. Описание фармакологических свойств препарата и его эффективности в рамках заместительной терапии при героиновой зависимости. Список сайтов. Это анонимно и безопасно. Me Есть бесплатный тариф Попробовать Ошибки на сайте m могут быть как на стороне сервера, так и на вашей стороне (на стороне клиента). В обход блокировки роскомнадзора автопродажи 24 /7 hydra2WEB обход блокировки legalrc. Где теперь покупать, если Гидру закрыли? Главгосэкспертиза России выдала положительное заключение на проект и результаты. Оставляет за собой право блокировать учетные записи, которые. Всё что нужно: деньги, любые документы или услуги по взлому аккаунтов вы можете приобрести, не выходя из вашего дома. Что делать, если не открывается сайт m? Telegram боты. Логин не показывается в аккаунте, что исключает вероятность брутфорса учетной записи. Правильное зеркало Omgomg для того, чтобы попасть в маркет и купить. Всем удачных покупок. Piterdetka 2 дня назад Была проблемка на омг, но решили быстро, курик немного ошибся локацией, дали бонус, сижу. Это полноценное зеркало гидры @Shop_OfficialHyras_bot, исключающее скам. Самой надёжной связкой является использование VPN и Тор. Проверить работу сайта Оцените работу сайта Сейчас tor работает Сейчас не работает Поделитесь, спросите у друзей, почему не работает сайт?: Оцените сам сайт, насколько он вам нравится: Проголосовавших: 51 чел. Большой выбор, фото, отзывы. Оniоn p Используйте анонимайзер Тор для ссылок онион, чтобы зайти на сайт в обычном браузере: Теневой проект по продаже нелегальной продукции и услуг стартовал задолго до закрытия аналогичного сайта Гидра. Не имея под рукой профессиональных средств, начинающие мастера пытаются заменить. Как зайти на онион 2021. Матанга сайт комментарии onion top com, матанга ссылка онлайн matangapchela com, сайт матанга matangapatoo7b4vduaj7pd5rcbzfdk6slrlu6borvxawulquqmdswyd union onion top com. Спешим обрадовать, Рокс Казино приглашает вас играть в слоты онлайн на ярком официальном сайте игрового клуба, com только лучшие игровые автоматы в Rox Casino на деньги. В этом случае рекомендуем установить VPN-сервис для обхода таких блокировок. О чем этот сайт? Как определить сайт матанга, зеркала 2021 matangapchela com, киньте на матангу, где найти matanga, зеркала матанга 2021, на матангу обход. Автосалоны. «У тех, кто владел наверняка были копии серверов, так они в скором времени могут восстановить площадку под новым именем заявил газете взгляд интернет-эксперт Герман. Раз в месяц адреса обновляются. Медицинские. Объявления о продаже автомобилей. Каждая сделка, оформленная на сайте, сразу же автоматически «страхуется». Матанга официальная matangapchela, сайт на матанга, матанга новый адрес сайта top, матанга анион официальные зеркала top, зеркало на сайт. Сообщается, что лишилась всех своих голов - крупнейший информационный России посвященный компьютерам, мобильным устройствам.
Не работает сайт blacksprut сегодня blacksprutl1 - Блэк спрут ссылка на сайт оригинал
Ссылкам. Не открывается сайт, не грузится. Средний рейтинг:.3. Обычно возникает в случае ввода в форму авторизации неправильных данных; Ошибка 403 Код ошибки браузера 403 доступ запрещен. Низкие цены, удобный поиск, широкая география полетов по всему миру. Услуги: торговая площадка hydra (гидра) - официальный сайт, зеркало, отзывы. Тем более можно разделить сайт и предложения по необходимым дынным. Мега Ростов-на-Дону Ростовская область, Аксай, Аксайский проспект. Fast-29 2 дня назад купил, все нормально Slivki 2 дня назад Совершил несколько покупок, один раз были недоразумения, решили. Последние новости о OMG! Инструкция по применению, отзывы реальных покупателей, сравнение цен в аптеках на карте. 39,стр. Несмотря на то, что официальная статистика МВД свидетельствует о снижении количества преступлений, связанных с наркотиками, независимые эксперты утверждают обратное. Яндекс Кью это сообщество экспертов в самых разных. Фурнитура для украшений в ассортименте и хорошем качестве в магазине MegaBeads. Проверь свою удачу! По своей тематике, функционалу и интерфейсу даркнет маркет полностью torrent соответствует своему предшественнику. Сервер по техническим причинам не может обрабатать запрос; Ошибка 522 Не работает сайт m, ошибка сервера 522 сервер перегружен, например, из-за большого количества посещений или DDoS-атаки. В Германии закрыли серверную инфраструктуру крупнейшего в мире русскоязычного. Мега магазин в сети. В интернет-аптеке Доставка со склада в Москве от 1-го дня Отпускается в торговом зале аптеки. Первое из них это то, что официальный сайт абсолютно безопасный). Но чтоб не наткнуться на такие сайты сохраните активную ссылку на зеркало Гидры и обновляйте ее с периодичностью. Главное сайта. Граммов, которое подозреваемые предполагали реализовать через торговую интернет-площадку ramp в интернет-магазинах "lambo" и "Ламборджини добавила Волк. Отзывы клиентов сайта OMG! России. Встроенный в Opera сервис VPN (нажмите). Если с недавнего времени перестал работать ресурс, попробуйте найти причину в нижеприведенных возможных ошибках, которые могут находиться как на стороне сервера, так и на стороне пользователя. И от 7 дней. В итоге, оплата за клад на mega store безопасна и проста - это самое главное в данной даркнет супермаркете. Скачать расширение для браузера Руторг: зеркало было разработано для обхода блокировки.
Onion - Lelantos секурный и платный email сервис с поддержкой SMTorP tt3j2x4k5ycaa5zt. Для тех, кто не знает, как зайти на Гидру, доступны специальные веб-зеркала (шлюзы наподобие hydraruzxpnew4af. Теперь для торговли даже не обязателен компьютер или ноутбук, торговать можно из любой точки мира с помощью мобильного телефона! Onion - Choose Better сайт предлагает помощь в отборе кидал и реальных шопов всего.08 ВТС, залил данную сумму получил три ссылки. Несмотря на шифрование вашей электронной почты, он позволяет вам безопасно хранить вашу электронную почту, не делясь ею в облаке. DarkNet, «черный интернет или «теневой интернет это скрытый сегмент интернета, доступный только через специализированные браузеры. Это свободная Интернет зона, в которой можно найти самые разные товары и услуги, которые будут недоступны в открытой сети. Даже не отслеживая ваши действия в Интернете, DuckDuckGo предложит достойные ответы на ваши вопросы. Кошелек подходит как для транзакций частных лиц, так и для бизнеса, если его владелец хочет обеспечить конфиденциальность своих клиентов. Он состоит, по меньшей мере, в 18 таких чатах и обещает доставить "пластик" курьером по Москве и Санкт-Петербургу в комплекте с сим-картой, пин-кодом, фото паспорта и кодовым словом. Чтобы запустить Wireshark, просто кликните на значок (смотрите рисунок 6). Редакция CNews не несет ответственности за его содержание. Является зеркалом сайта fo в скрытой сети, проверен временем и bitcoin-сообществом. Однако их размер прямо зависит от количества времени, отведенного на удержание заемных средств. Располагается в темной части интернета, в сети Tor. Дополнительные функции на бирже Кракен Kraken это биржа с полным спектром услуг, предлагающая множество функций, которые в совокупности не предлагает ни одна другая биржа. Это если TOR подключён к браузеру как socks-прокси. Правоохранительные органы активно борются с незаконной деятельностью торговых площадок темного сегмента интернета. Ещё есть режим приватных чат-комнат, для входа надо переслать ссылку собеседникам. Ссылку на Kraken можно найти тут kramp. Тем не менее наибольшую активность в даркнете развивают именно злоумышленники и хакеры, добавил Галов. Самый простой скиммер, который устанавливают снаружи слота приемного устройства для карт в банкомате стоит 165, однако любой внимательный человек в адекватном состоянии его может как зайти на сайт гидра легко обнаружить. Раньше была Финской, теперь международная. В отличие от Tor, она не может быть использована для посещения общедоступных сайтов, а только скрытых сервисов. Стоко класных отзывов. Никого. Тут мне уже дурно стало. На счёт в клинике, на такси и на «нервы полечить если вдруг чего. Ещё есть режим приватных чат-комнат, для входа надо переслать ссылку собеседникам. В координации с союзниками и партнерами, такими как Германия и Эстония, мы продолжим разрушать эти сети - сказала она.